I did a keynote presentation at the SIGCOMM'15 HotMiddlebox workshop, "Mobile TCP optimization - Lessons Learned in Production". The title was set before I had any idea of what I'd really be talking about, just that it'd be about some of the stuff we've been working on at Teclo. So apologies if the content isn't an exact match for the title.
This post contains my slides, interleaved with my speaker's notes for that slide. It won't be an exact transcription of what I actually ended up saying, they were just written to make sure that I had at least something coherent to say re: each slide. We've got an endless supply of network horror story anecdotes, and I can't actually remember which ones I ended up using in the talk :-/
I'm particularly happy that my points on transparency of optimization got a positive reception. To us it's a key part of making optimization be a good networking citizen, and has seemingly been getting short shrift so far. Hilariously the other TCP optimization talk at the workshop brought up a transparency issue we'd never had to consider, lack of MAC transparency causing a Wifi security gateway to think connections were being spoofed.
Thanks to Teclo for letting me talk about some of this stuff publicly,
and to everyone who attended HotMiddlebox. It was a lot of fun, and I
got a bunch of useful information from the hallway discussions.
Table of Contents
- Introduction
- Background
- Implementation 1/2
- Implementation 2/2
- TCP optimization
- An optimized connection
- Transparency
- Simple optimizations
- Speedups
- Buffer management
- Effect on RTTs and packet loss
- Burst control
- Things we learned along the way
- Don't rely on hardware features
- Two mobile networks are never equal
- Reordering
- Strange packet loss patterns
- Bad or conflicting middleboxes
- O&M is a lot of work
Presentation

Hi, good morning everyone. I'm Juho, and I'll be talking about the
mobile TCP optimization system we've been working on at Teclo
Networks.

I'll start with a tiny bit of background on the product, then show how
it works, how we think about TCP optimization and some results. And
finally I'll go through about some of the things we learned while
growing this from a prototype to a product that can be deployed in
real operator networks.

We're a Zurich based startup that's been working on TCP optimization
for about 5 years now, with the first production deployments over 4
years ago so we've got a bit of experience at this point. We've been
in live traffic in around 50 mobile networks with about 20 commercial
deployments. This includes all kinds of radio technologies (2G, 3G,
LTE, WiMAX, CDMA) and anything from small MVNOs with 100Mbps of
traffic to multi-site installations at major operator groups with
100Gbps of traffic.

This is all done with standard hardware, normal Xeon CPUs and Intel 82580 or 82599 NICs. The only exotic component in our typical setup are NICs with optical bypass for failover. This scales up to 10 million connections and 20Gbps of optimization in a single 2U box.
Our normal method of integration is to function as a bump in the
wire with no L2/L3 address, preferably on the Gi link next to the
GGSN. This the last point in the core network that deals with raw IP
before it gets GTP encapsulated. So we have two network ports, one
is connected to the GGSN and the other is connected to the next hop
switch. From their point of view it's just a very smart piece of
wire.

We've got a completely custom user space TCP stack. We started from scratch rather than from an existing implementation since our method of splitting the connection into two separate parts without sacrificing transparency would be hard to retrofit into an existing stack. Packet IO is done with our own user space NIC drivers; basically map the PCI registers and a big chunk of physical memory for frame storage, and manipulate the NIC rx and tx descriptor rings directly. It's not a lot of code, less than 1000 lines, and has some really nice properties like complete zero copy implementation even for packets that we buffer for arbitrary amounts of time.
The operating system is only involved with the control plane, the
data plane is all in user space. One reason for that is obviously
performance, but we think it's also a big win all around. Everything
is always so much easier when you're working in user space;
programming, debugging, testing, deployment.

So what do I mean by TCP optimization?
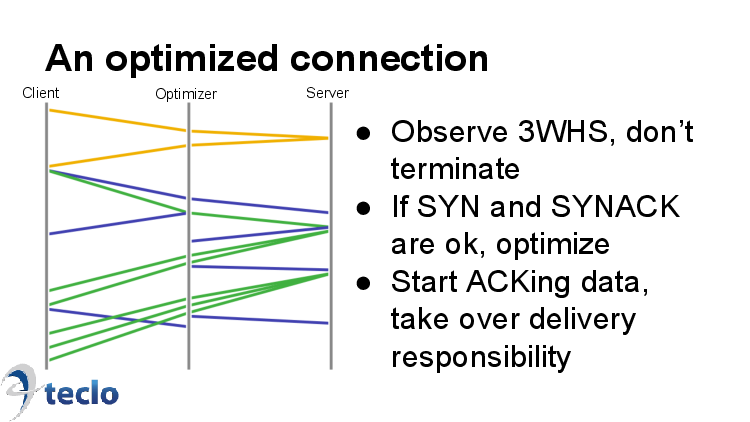
An optimized connection looks something like this. We pass the initial handshake through unmodified; yellow SYN from client to server, yellow SYNACK, and the final ACK in blue. Up to this point we're just a totally transparent network element. If there's anything odd about the connection setup, we'll just leave that connection unoptimized and continue forwarding any packets straight through.
But in this case everything went fine, so from that point on we'll ACK any data packets and take responsibility for delivering them. So here in green we have the request; we send an ACK to the client, and the segment toward the server. The server sends the first part of the response which we ack, and then send a new batch of data to us.
So it's kind of a hybrid. Not a terminating split-TCP proxy, but
thanks to acknowledging data is a lot more effective than a Snoop
proxy.

Since we don't terminate the connection, we can be fully transparent in TCP options and sequence numbers. This provides us with some really nice advantages.
First, we can stop optimizing connections at almost any time without breaking them. As long as we have no undelivered data buffered for the connection, the endpoints agree on the connection state and can just pick it up. This means we can have pretty short idle timeouts, a couple of minutes rather than 15 minutes. And if something odd happens? Just stop optimizing. This is also really nice for upgrades; we just stop optimizing connections, wait about a minute for all the buffers to drain, and take the system to bypass without interruption of service.
It deals very nicely with asymmetric routing. Sometimes something goes wrong with the integration, and we only get the uplink or downlink packets for some of the traffic. If we see only the SYN and the ACK but not the SYNACK, we'll just skip optimizing the connection. The same if we see the there's a loopback route where we see the SYN twice, once in each direction.
One problem with middleboxes is that they make it hard to introduce new TCP options, say multipath TCP of TCP fast open. Terminating middleboxes will essentially eat the unknown options. In our design a SYN with unknown options will just be passed straight through and we'll let the endpoints take care of the rest. There's a closely related issue of protocols that claim in the IP header to be TCP in order to bypass firewalls, but actually aren't. Again these would be broken by termination.
Finally, terminating proxies will often end up with a different MSS
on the two sides of the connection. So it's supposed to send packets
of at most 1380 bytes toward the client, but the server sends it
data in chunks of 1460 bytes. This repacketization increases load,
but also increases protocol overhead when packets are split
suboptimally. In the worst case there will be a substantial amount
of tiny segments in the middle of the TCP flow, which is problematic
for a lot of mobile networks. In our design the segments can just be
passed through as-is, with at most a bit of tweaking to the IP and
TCP headers.

Some of the optimizations we can do are standard fare. Latency splitting speeds up the initial phase of the connection, especially if the server is old and still has an initial congestion window of 2/3/4. Likewise if the connection is bottlenecked on the receive window, reducing the effective latency improves steady state throughput.
If there's packet loss, having the retransmission happen nearer to the edge means we react faster to it. We can also make better decisions thanks to knowing it's a radio network and applying some heuristics to the packet loss patterns (more on that later). We don't have any fancy congestion control algorithm, our experience is that it's just not an area where you can gain a lot.
One thing you have a lot in mobile networks is either the radio
uplink or downlink freezing completely for very long times relative
to normal RTT. This triggers a lot of bogus retransmit timeouts in
vanilla TCP stacks. We never use retransmit timers, and detect tail
losses using probing instead. This allows faster recovery in cases
where the full window was really lost. There's also no risk of
misinterpreting an ACK of the original data as an ACK of the
retransmitted data, which might cause confusion otherwise.
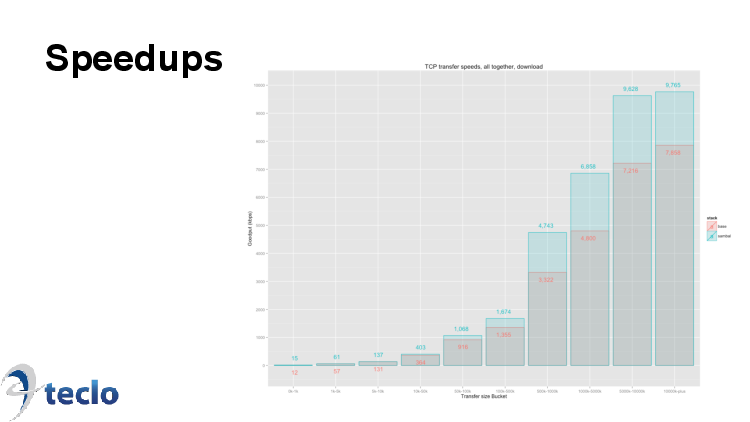
How well does it work? Here's some results from a trial in a European LTE network last winter. These are average throughput numbers for downloads, bucketed by transfer size. Optimized results in blue, unoptimized in red. What we see is little if any acceleration for tiny files (there's not much scope for optimization when all the data fits in the initial window), and anywhere from 10-40% speedups for larger transfers.
Just to clarify, these are results from live traffic rather than any kind of synthetic testing, looking at the throughput of all TCP connections going through the operator's network with alternating days of optimizing 100% of the traffic with days of optimizing none of it.
(N.B. Measurement seemed to be a somewhat sensitive issue, with doubts expressed regarding whether we were really doing it in a statistically robust manner, and whether averages are really a sensible way to represent the information.
Performance measurements in mobile networks are indeed a harder problem than you'd think. Unfortunately it's also a subject I could talk about for an hour and this was a 40 minute talk that needed to cover a lot more ground. I might need to write a separate post on this subject.
But suffice to say that we do the live traffic measurements in a way
that tries to minimize effects from weekday / month of day trends,
and over a long enough period of time that the diurnal cycle is
irrelevant. Averages are indeed not a good measure from an academic or
even engineering point of view, but using anything else is miserable
commercially. You don't want to spend the first 30 minutes of a
meeting by explaining exactly how to interpret probability density
function or CDF graphs.)

Here's a more interesting optimization. Buffer management which is our feature for mitigating buffer bloat. Mobile networks are usually tuned to prefer queueing over dropping packets. And internet servers in turn are always going to ignore queuing as a congestion signal since RTT-based congestion control schemes will always lose out in practice due to the tragedy of the commons. So the queues will be filled to the brim in even pretty normal use. The most extreme case we've seen had queues of 30 seconds. Obviously unusable for anything, but even much a few hundred milliseconds of extra RTT will make interactive use painful.
Now, in mobile networks these queues are almost always per-user rather than per-flow or global. So what we do is handle all of the TCP flows of a single user as a unit. We determine the amount of data in flight across all flows that both keeps RTTs at an acceptable level but also doesn't starve the radio network of packets. When the conditions change, we adjust that estimate. This quota of in flight bytes is then split between the all the flows of the user, and we give all connections their fair share of it. So the batch download won't completely crowd out the web browsing.
This is independent of per-flow congestion control, there are some
practical reasons why you only want to do packet loss based
congestion control on a flow level. It won't work when done
per-subscriber.
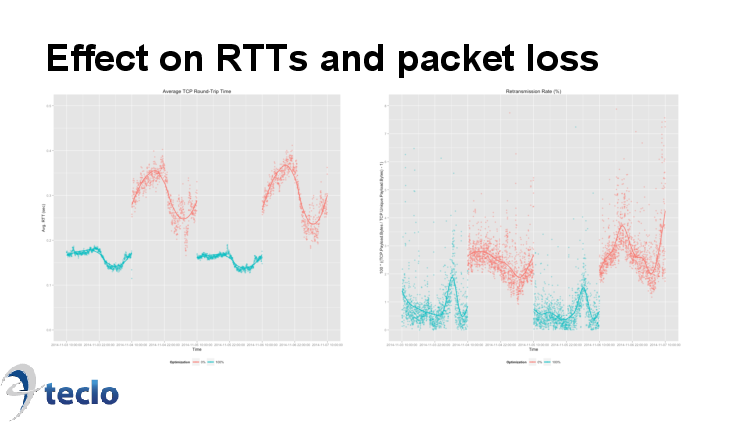
How well does it work? Here's some results from the same network as the previous example. Here we have results from 4 days of testing, with time on the X axis. The samples in blue are from the days when all traffic was being optimized, the red samples from days with optimization turned off. The graph on the left has average RTT on the Y axis. On the optimized days it's pretty stable at around 165ms, on the unoptimized days there's more variation and the averages are much higher, 320ms. So it's an almost 50% reduction in average RTT. On the right hand graph we have retransmission rates on the Y axis. For optimized days they are mostly under 1% (average 0.8%) and for unoptimized mostly above 2% (average 2.6%). That's a roughly 70% reduction in retransmissions.
This data is from the same set of testing as the results from a
couple of slides back. So these RTT reductions aren't coming at the
expense of performance. Instead we're getting big improvements in both
RTT and in throughput.

Another thing we've noticed is that even surprisingly modest bursts of traffic can cause packet loss, for example when traffic gets switched from 10G to 1G links. And there are all kinds of mechanisms in TCP that can cause the generation of such bursts. ACK bunching, losing a large number of consecutive ACKs, or losing a packet when the full receive window's worth of data is in flight (the delivery of the retransmitted packet will open up the full window in one go).
Whatever the mechanism, it turns out that you don't want the TCP
implementation to send out hundreds of kilobytes for a single
connection in a few microseconds. Instead it's better to spread the
transmits over a larger period of time. So not 200kB at once but
instead 20kB at 1ms intervals. In one network this kind of pacing
reduced the observed packet loss rate on large test transfers from
over 1% to under 0.2%.

Here's some of the things we learned the hard way.

Every time we depend on a hardware feature we end up regretting it. They can never be used to save on development effort, because next month there will be new requirements that the hardware feature isn't flexible enough to handle. You always need to implement a pure software fallback that's fast enough to handle production loads. And if you've already got a good enough software implementation, why go through the bother of doing a parallel hardware implementation? The only thing that'll happen is that you'll get inconsistent performance between use cases that get handled in hardware vs. use cases that get handled in software. A few examples:
Most common issue is needing to deal with more and more exotic forms of encapsulation. VLANs are fine, hardware will always support that. Double VLANs might or might not be fine. Some forms of fixed size encapsulation are fine. Multiple nested layers of MPLS, or GTP with its variable length header are a lot more problematic. A canonical example here is checksum offload for both rx and tx; there's hardware support that always eventually ends up being insufficient, and you can compute the checksums very fast with vector instructions on modern CPUs.
We've been using multiple RX queues for parallelization. So we assign one process to each core, with each one having a separate receive queue. We originally did this with basic RSS hashing, but that quickly became insufficient. Smart people would have stopped at that. But we're idiots, and read the documentation on this wonderful semi-programmable traffic distribution engine built in to the NICs we used, call the Flow Director. Up to 32k rules with various kinds of matching. Awesome.
But then we needed to deal with
virtualization. SR-IOV looks just perfect for our needs; the virtual
machine gets its virtual slice of the network card that's for all
intents and purposes identical to the real hardware. Except... It only
has a maximum of 8 queues when physical hardware can do up to
128. We need more parallelization than 8 queues. And of course
encapsulation is an issue too, even the Flow Director isn't flexible
enough for every use case we've seen. So everything needs to be
architected around just a single RX queue and doing the traffic
distribution fully in software.

We initially thought that we'd just write the system once, deploy it everywhere, and roll in money while doing no work. But it turns out that no two networks are quite the same. There's often new kinds of performance issues or the existing methods of integration don't work in a network. We love the first case from a commercial point of view, since every problem is an opportunity for a performance improvement. We hate the latter, since supporting new integration methods brings no real value, it's just a cost of doing business. But in both cases the end result is that there's a fair bit of code that's not exercised in normal use and is liable to code rot.
Automated deterministic unit testing has been absolutely key in
maintaining our sanity with this, and my only regret there is not
planning for it from the first line of code and having to retrofit
it in. Compared to the normal network programming workflow it's
just such a huge productivity boost to be able to run hundreds of
TCP behavior unit and regression tests in a few seconds. Things that
get fixed stay fixed. We're also able to automatically generate ipv6
test cases from our ipv4 tests. If we didn't do it, there's a good
chance that our ipv6 support would rot away very quickly.

I'll give a couple of examples of performance issues I thought were interesting.
The folklore around mobile networks is that there will never be any
reordering. So our initial design was actually based on aggressively
making use of that assumption. Turns out not to be true in
practice. For equipment from one particular vendor we've seen small
packets get massively reordered ahead of large ones. We're talking of
reordering by 30 segments or over 50ms. This is particularly bad if
there's a terminating HTTP proxy in the mix, and MTU mismatches on the
southbound and northbound connections cause the proxy to generate lots
of small packets. And reordering is poison for TCP. So we had to
develop special heuristics to detect and gracefully handle this case.

Then there's strange patterns of packet loss or packet corruption. I talked earlier about the burst control feature that mitigates problems caused by packet loss from 10G to 1G switching. But this one is maybe even more mysterious.
One network was regularly losing some or all packets right at the start of the connection. So the handshake would go in, the request would go out, and then the response was dropped somewhere in the RAN. Losing the initial window of packets is of course just about the worst thing you can do to TCP. And this only happened in one geographical region that was using a different radio vendor than the rest of the country. Our best guess was that it was somehow related to the 3G state machine transition from low power to high power mode.
We never did find out exactly what the issue was, getting that
sorted out was the operator's job. But again we needed some
specialized code, this time to handle packet loss after a period of
no activity different from packet loss in the middle of a high
activity period.

Operator core networks can have absurd numbers of chained middleboxes. So you'll have a series of traffic shaper, TCP optimizer, video optimizer, image and text compressor, caching proxies, a NAT and a firewall, all from different vendors. When something goes wrong, it can take a lot of effort to just locate which component is at fault. The default assumption always seems to be that it's the most recently added box, which to be fair is a pretty good heuristic to apply. Things are even worse if it's not strictly a problem with a single network element, but in the interactions of several nodes. And these middleboxes are configured once, probably not looked at again for a very long time unless someone notices a problem, and the combination is never tuned holistically.
Maybe a canonical example of this is MTU clamping. In mobile networks you generally want a maximum MSS of 1380 to account for the GTP protocol overhead. Often this is done by making e.g. the firewall clamp the MTU. This works great until a terminating proxy is added south of the firewall, such that the clamping doesn't apply to the communication between the client and the proxy but does apply to the communication between the proxy and the server. This is exactly the wrong way around, and it's easy to miss since things will still work, just inefficiently.
HTTP proxies are frequently really badly configured from a TCP standpoint, which makes some sense since that's not their core competence. A HTTP proxy is usually there to do a specific function like caching, compression or legal intercept. It's not there to optimize speed. But you'll see things like the proxy not using window scaling for the connection to the server, or still using a initial congestion window of 2. These are things that should not exist in 2015.
There are proxies that freeze the connection for a few seconds on receiving a zero window, which is normally not a big deal since zero windows are rare. But a bit of a problem if you have another device right next to the proxy ACKing the data - for example a TCP optimizer. (We had to develop a special mode that'd never emit zero windows and instead do flow control through delaying ACKs progressively more and more as the receive buffers fill up). We even saw a HTTP proxy that had been configured to retransmit 15 segments instead of one segment on a retransmit timeout. Since RTOs caused by delays rather than full packet loss are of course really common in mobile, this proxy was spewing out amazing amounts of spurious retransmissions.
One funny interaction we see all the time is having a TCP optimizer
right next to a traffic shaper. So you have one box whose job it is
to speed things up, and another that tries to slow things down. It's
an insane way of doing things - these two tasks should maybe be done
by the same device.

I've been just talking about the data plane in this presentation, since that's the part I'm responsible for. But it's really important to note that the data plane alone is not a product you can sell.
You need quite a lot of sophistication on the control plane too to get something that can be deployed in operator networks. It's a lot more work than one might think, in our case the management system probably took at least as much effort as the traffic handling, with three full rewrites and a fourth one ongoing. So there's a Juniper-style CLI for configuration, a web UI for simple configuration and statistics, a counter database, support for all kinds of protocols for getting operational data in and out of the management system, and so on.
If anyone here is planning on turning research into a product, you
need to budget a lot more time for this stuff than you think.

Thanks a lot for your attention, we should have some time for questions now. If you want to get in touch with me for some reason, here's my contact details.