Chapter the Third, where our hero discovers the hazards of conservative GCs, iterates through page tables and eats his own dogfood.
In the normal SBCL build process PURIFY is run just before the core is saved to disk. On x86-64 this results in about 38MB in the non-collected spaces. When a full GC is done instead of the purify the dynamic space size is 55MB. This difference in collection efficiency is somewhat mysterious (apparently I'm not the first one to notice it, there are at least two FIXMEs related to this issue in the source). Turns out that the whole 45% increase in space usage is caused by GC conservativeness, which at least I found really surprising. I added a simple hack to the GC for a non-conservative GC mode that can only be run just before saving the core, and another one to promote the whole dynamic space to the oldest generation when the core is loaded. This gives a pretty good approximation for a static space with a write barrier.
With all of the data behind the write barrier, a GC with no data in the
nursery should be really, really cheap. However, on my computer it was
still taking a relatively hefty 3.5ms (compared to about 10ms on
vanilla SBCL). A oprofile run revealed that the main bottleneck was
iterating through the page table. The GC has no data structure that
only holds the pages for some particular generation, so every time we
want to apply an operation to every page in a generation (which
happens very often) we need to iterate through the whole table. In
an email to Luke Gorrie
on this issue I wrote "this looks like it should be easy to fix".
It turned out to be trickier in practice (who would've thought that hacking GCs is actually hard?), but after a couple of all-nighters I now have a version that mostly works. Each page is basically a node in a doubly-linked list (one list / generation). The lists are unsorted, but any block of pages in the same generation that are adjacent in memory are guaranteed to also be adjacent and in the same order in the list. This is sufficient to handle all but two of the use-cases for iterating through the whole table.
-
scavenge_newspace_generation_one_scan()needs to work through the pages in linear order. I don't quite understand why, but it's probably related to some magic that's needed to handle allocation into a generation that's currently being scavenged. Enlightenment on this issue is not expected. -
update_x86_dynamic_space_free_pointer()(a function that's not x86-specific in any way) updateslast_free_page, a wonderfully named variable that's supposed to contain the index of the first page that follows the last non-free page. This can't be easily derived from the unsorted lists, but there might be other cheap ways to get at the data.
A GC with an emptyish nursery now takes about 1.5ms, which isn't quite
as bad. If you aren't interested in how quickly
(time (dotimes (i 1000) (gc))) executes, try this pretty cl-bench
picture instead:
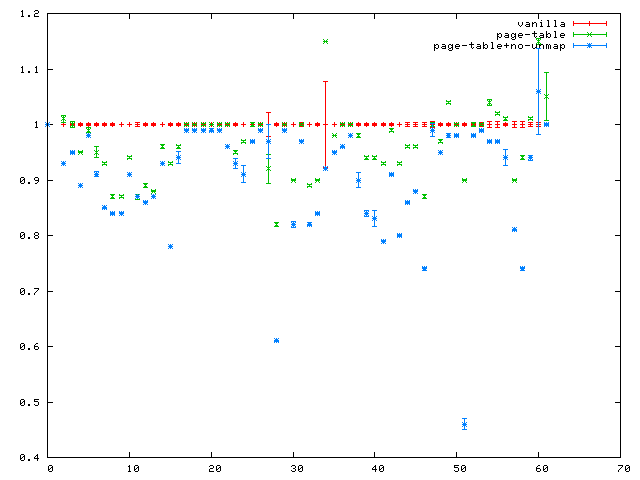
Stuff to do:
-
The dynamic space needs to be compacted when doing the final GC before saving the core. Otherwise we'll dump a lot of empty pages and probably double the size of the core file.
-
As you can see from the graph, clearing the memory with
memset(blue) instead of the SBCL/Linux defaultmunmap+mmap(green) is way, way faster. Unfortunately someone has been here before, but this really looks worth a second look. -
Pinned pages get no write-barrier, which means that they need to be scavenged on every GC. Why? Every call to GC ends up creating quite a few pinned pages, and they get tenured instead of collected.
PS. I thought my hacked version was reasonably stable, since it was able to run the ansi-test suite with no extra failures. Nope. My blog software crashes to LDB when trying to publish this post. Time to revert, and forget for a moment about eating my own dogfood.