I wanted to compute some hash values in a very particular way, and couldn't find any existing implementations. The special circumstances were:
- The keys are short (not sure exactly what size they'll end up, but almost certainly in the 12-40 byte range).
- The keys all of the same length.
- I know the length at compile time.
- I have a batch of keys to process at once.
Given the above constraints, it seems obvious that doing multiple keys in a batch with SIMD could speed thing up over computing each one individually. Now, typically small data sizes aren't a good sign for SIMD. But that's not the case here, since the core problem parallelizes so neatly.
After a couple of false starts, I ended up with a version of xxHash32 that computes hash values for 8 keys at the same time using AVX2. The code is at parallel-xxhash.
Benchmarks
Before heading off into the weeds with the details, below are a couple of pretty graphs showing performance with different key sizes for a few different implementations: CityHash64 since it's been my default hash function for years, xxHash64 since my parallel implementation was based on xxHash32, and MetroHash64 since I saw people suggesting it was the fastest option for small keys. I did not include FarmHash since it was consistently slower than CityHash for all key sizes.
Finally, to isolate the benefits of specializing for the statically known key sizes, I've included a scalar version of xxHash32. It has exactly the same structure as the parallel version, except for not using SIMD [0].
All implementations computed hashes for the same number of keys;
the parallel implementations did it 8 keys at a time, the others
did them sequentially. The tests were run on a i7-6700 and GCC
6.3.0, with -O3 -march=native
-fno-strict-aliasing. The benchmark code is in the
repository, but you'll need to bring your own copies of the
external hash table libraries.
First, let's look at the time take per key for key sizes relevant to my use case (this graph is 4-72 bytes, but as mentioned before the most interesting range for me is around 12-40 bytes):
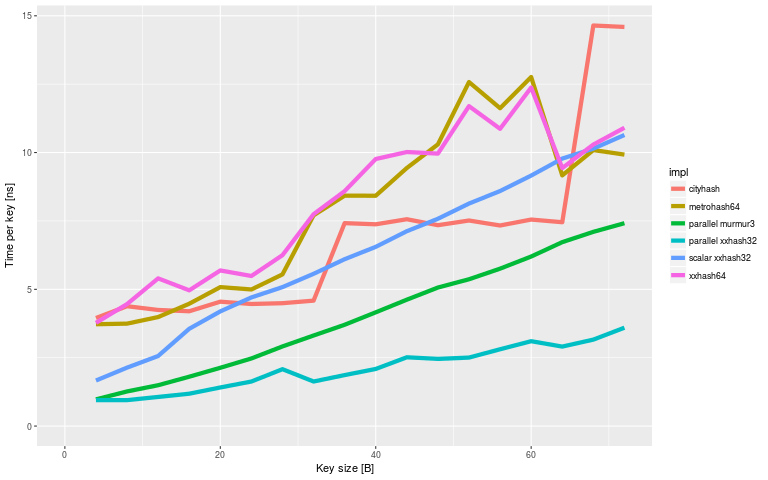
That looks pretty nice, with very significant speedups compared to the alternatives on all the key sizes. With larger key sizes the parallel Murmur3 (my first try) quickly runs out of steam, but the parallel xxHash32 stayed ahead of the pack. We'll switch to showing time per byte rather than time per key here.
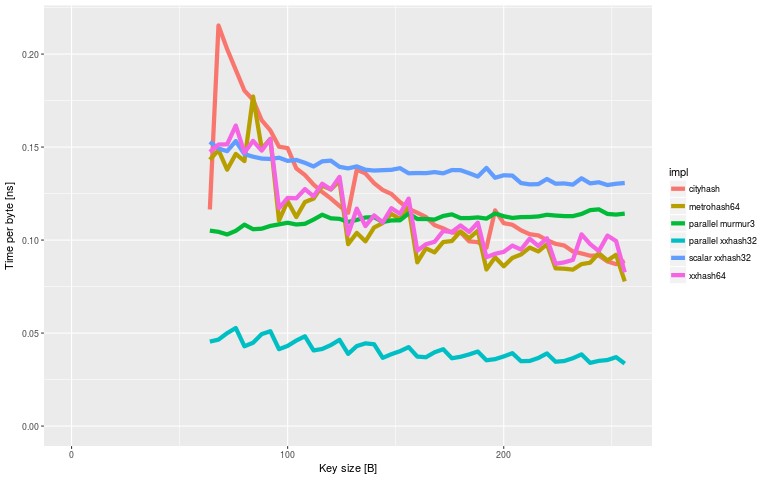
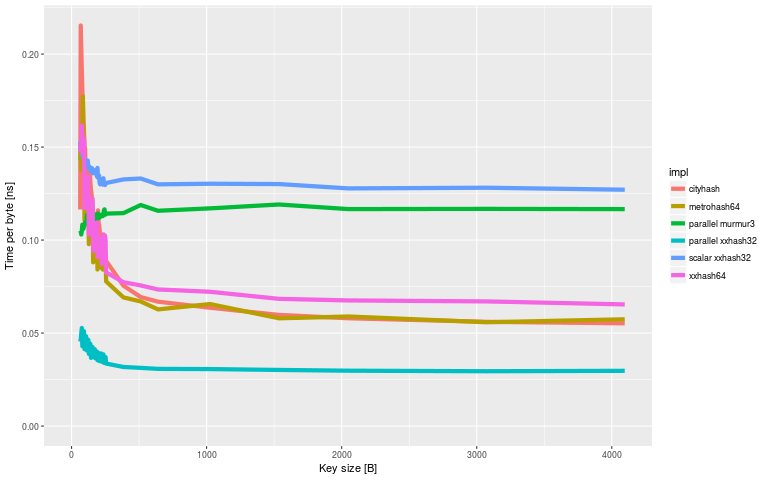
And at 512 bytes or so, the time per byte has flattened out completely:
Don't look under the rug
So what are the downsides? Why wouldn't everyone use this?
The most glaring problem is that most applications don't do hash computations in parallel. Either it's going to be fundamentally impossible, or at least it will require a major restructuring.
Second, I've swept a small detail under the rug: the parallel implementations were using column-major order for the data. It's the natural way to structure this. The timings above do not include a row-major to column-major conversion step. That's because my application was already using column-major anyway. But if that weren't the case, it's totally possible that the conversion step would wipe away a good chunk of the gains. (What about scatter-gather? See below).
Third, I suspect that most uses of hash tables use strings as keys. This code will not work at all in that use case. Not only do the sizes of keys have to be statically known, but (another detail I skimmed over above) they also need to be a multiple of 4 bytes long. Basically, I want to use structures as hash keys; not sure how many other people also need that.
And fourth, the parallel implementations were using the 32-bit variants of the algorithms due to reasons that I'll explain later. That does not make the benchmarks unfair (the 64-bit versions are faster than the 32-bit ones). But some applications will need those extra bits in the hash value. This code can't provide it.
So while this should work fine for me (though that still remains to be seen), it might not be a very large ecological niche.
What's interesting about this?
Converting from the scalar version to the parallel version is a fairly mindless process, not many insights to be had in that part. But while doing this, I bumped into some interesting aspects on the periphery.
Rotates
All the fast and high quality hash functions I looked at seemed to be descendants of Murmur, and used rotates as their primitive of choice for moving bits down. This is most likely because x86 has a dedicated rotate instruction, while most other methods require two instructions, e.g. shift+xor. For AVX that's not the case, and you need to synthesize the rotate from two shifts and a xor/or.
Based on some quick testing, a single-instruction replacement could give a 40% speedup, and a two instruction replacement a 20% speedup. There's not a huge number of single instruction options available though: horizontal 16-bit addition/subtraction, or the 8-bit shuffles. I suspect neither would work very well due to the effects aligning at an 8 bit boundary. With two instructions a shift+xor is probably the best option. Would be interesting to see if the best speed/quality tradeoff is different for AVX than for x86.
Multiplies
These days new hash functions are mostly built with 64*64->64 multiplies. We won't have that in SIMD until AVX-512 (and given the way things are going, I wonder if a general purpose CPU using AVX-512 will actually ever launch). Synthesizing a 64-bit multiply from 32-bit multiplies doesn't seem viable for this use case. So for this use case, we really want to look at the hash functions defined a few years ago rather than the latest hotness.
Memory layout
Like I mentioned earlier, my data is already in column-major order so I didn't need to worry about wrangling that. But at one point I thought that it'd be nice to provide an alternate version that would work on row-major data. That's what scatter-gather is for, right?
Nope, the gather instructions are just unbelievably slow, and additionally for some reason prevented compilers unrolling the Murmur3 loop, for a 4x performance loss. (Even on GCC 6.3 and clang 3.8). In theory the xxHash inner loop should be better for the gather instructions, since at least there you're not depending on the compiler unrolling to get multiple parallel loads going. But the results there were only marginally less worse.
Auto-vectorization
After having written the version using intrinsics, it occurred to me that I really should have started off with just writing out plain C++ with the same semantics, and see if it auto-vectorizes. Because this really looks like it should be a very easy case. And while the transformation from a scalar version to using intrinsics is not too bad, the transformation to standard C++ expressing the same order of operations on the same memory layout is easier yet. The theoretically auto-vectorizable code certainly looks very pretty compared to the AVX intrinsic soup.
But ignoring aesthetics, the results were mixed. GCC 6.3 seemed to vectorize everything perfectly. GCC 4.9 [1] missed something (I didn't track down exactly what) that cost about 25% performance. And Clang 3.8 did nothing at all, with the plain-C++ version being 150% slower than the version using intrinsics. So still a bit on the fragile side. But this is the best showing for auto-vectorization that I've experienced so far.
(The GCC 4.9 case is particularly annoying; it would have been easy to write the auto-vectorizable version first, see the speedups and think auto-vectorization was working, but miss that it was still leaving a lot of performance on the table).
32-bit output values
The other advantage of 64-bit operations is that the natural implementation will end up producing a 64-bit hash value. Now, for normal hash tables I'm totally OK with a single 32-bit hash value. But there's some use cases like Cuckoo hash tables or Bloom Filters where one would really like more key material.
Before moving from Murmur3 to xxHash, I experimented a bit with a version that would not only compute results for multiple different keys at once, but also do it with multiple different seed values. It was actually pretty efficient. I didn't end up redoing that work for the xxHash version though. Primarily since I don't actually need that version right now, and secondarily since I'm actually not sure of whether the different seed values will give different enough outputs for use in a probabilistic data structures.
(If anyone knows for sure whether the last bit is true or not, please let me know).
Is there a faster non-parallel hash function here?
As mentioned multiple times, computing multiple keys in parallel is a very niche use case. But based on the benchmark graphs for large key sizes, I wonder if there's a decent non-parallel hash function hidden here: compute the 8 32-bit streams in parallel and combining them at the end (or at certain block boundaries). After all, that's already what xxHash does on a smaller scale.
This seems like something that people would already have explored in the quest for faster and faster hashing for large key sizes. But I can't find any trace of such an implementation. Maybe everyone had already moved to 64-bit multiplies by the time AVX2 started to be widely deployed and 32-bit multiplies became the faster option again. Or maybe 32-bit hash values for large key sizes aren't actually a useful point in the design space.
Designing hash functions is hard. I explicitly did not want to invent a new one here, but just re-implement existing algorithms. I even went so far as to add in the "mix in the length of the key" steps, just so that I could verify my code against the reference implementations. Sure, it's a useless step given the length is constant. But it doesn't cost that much to do either, and lets me not worry about accidentally destroying the hash quality.
But if I wanted to burn some brain cycles on designing one and a lot of CPU cycles on running SMHasher... 32-bit multiplies + shift-xor, working 64 bytes at a time, and code organized in a way that makes it easy to auto-vectorize could be a pretty interesting place to start from.
Footnotes
[0] Note that I tried to make sure to isolate this to specializing for the key size, not to e.g. be able to hoist any computations outside the benchmark loop. AFAIK all implementations went through the same number of non-inlined function calls.
[1] Yes, it's a couple of years old. But that's Debian stable for you. And to be honest, a year ago our main compiler at work was still GCC 4.4. Compared to that, 4.9 feels pretty darn luxurious.
thank you for the nice writeup. It's a good starting point for vectorized hashing.
greetz & beatz,