Alexander Kjeldaas posted a nice cll article
about using the SB-SPROF disassembler integration. While reading
the disassemblies that Alexander had annotated, I noticed we were
using a memory-to-register XCHG instrution on the memory-allocation
fast-path for x86-64.
Quote from the message:
; 4A: 41C684249800000000 MOV BYTE PTR [R12+152], 0
(CLEAR INTERRUPT FLAG?)
; 53: 41C684249000000008 MOV BYTE PTR [R12+144], 8
(INDICATE UNINTERRUPTIBLE)
; 5C: 48C7C110000000 MOV RCX, 16
; 63: 49034C2440 ADD RCX, [R12+64]
; 68: 49394C2448 CMP [R12+72], RCX
; 6D: 765B JBE L2
(CALCULATE NEW END-OF-HEAP
AND SEE IF WE NEED TO
ALLOCATE MOVE MEMORY)
; 6F: 49874C2440 XCHG RCX, [R12+64]
(GET ALLOCATED MEMORY/
UPDATE END-OF-HEAP)
That looks reasonable, right? We want to exchange two values, and
XCHG is the shortest way to do that. Unfortunately it's not reasonable.
A memory-referencing XCHG has an implicit LOCK prefix, and therefore
acquires a lock on the memory system to ensure that the XCHG is atomic.
This is very slow compared to executing a simpler instruction, and really
not something that should be done every time we want to allocate 16 bytes
for a cons cell.
Luckily we don't actually need an atomic exchange here, since the code
can't be interrupted due to running inside a pseudo-atomic section, and the data that's being modified
is thread-local on threaded SBCL builds. The only reason XCHG is being
used is that when the code was written, no spare register was available
as a temporary for shuffling the values. Later on other needs for
a general scratch register surfaced, and R13 was assigned for this
(i.e. the register allocator never assigns any TN to R13). Now that the register is available, getting rid of
the XCHG is a three-line change.
(Alexander sent a further optimization to the allocation sequence
to sbcl-devel, but I haven't looked it yet).
Here's a graph of the CL-BENCH results before and after the change (the versions between 0.9.6.8 and 0.9.6.14 were fixes to esoteric CLOS/MOP bugs, which had no major performance effect according to the automated benchmarks). Y-axis is relative execution time compared to the reference implementation, in this case 0.9.6.8. X-axis is individual CL-BENCH tests, in the arbitrary order that CL-BENCH outputs them. Ideas on better ways to visualize this data are welcome.
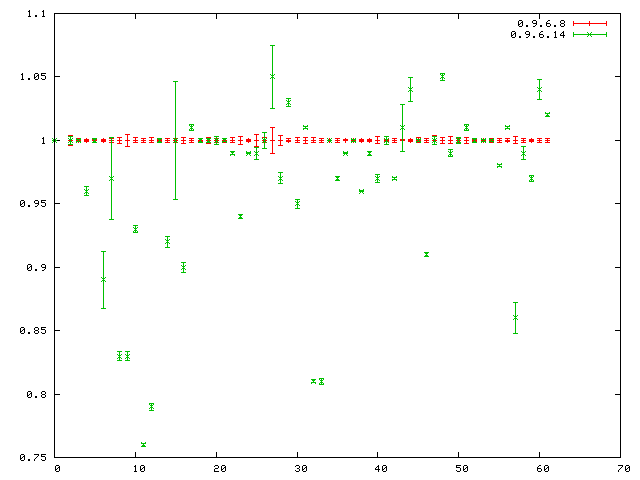
Some of the more consy tests get a 25% speedup from this change, which
is pretty good for such a tiny change. The 5%
speedup on the COMPILER benchmark that I reported in the commit message
was actually caused by some unrelated pretty-printer changes in the
same tree, so the winnage from this change wasn't quite as major
as I thought. I have no idea of what caused the large error
bars for .14.
The x86 port currently does all memory allocation by calling to C instead
of using this sort of inline allocation, since the inline allocation code
caused mysterious slowdowns on Pentium 4. The disabled code also does
a memory-referencing XCHG, which might well be the reason for the
slowdowns. Getting rid of the XCHG and re-enabling inline allocation
might give similar speedups on x86.
(This could be a reasonable project for someone who wants to
start hacking SBCL internals.)
In other news, I managed to advance the thesis a fair bit this week,
and don't need to feel guilty about spending some quality time
with SBCL this weekend instead of these small hacks.
Some of that time will probably be spent
merging stuff from the overflowing "unapplied
patches"-mailbox, and the rest in finishing and committing some long-dormant
changes from my local trees. The latter assumes I can find the changes;
for some reason the good stuff always ends up in trees with names like
clean, clean4, really-clean or pristine.