Every now and then someone proposes rewriting the SBCL garbage collector in Lisp (it's currently C). And every time this happens I have to spend a while figuring out why I don't like the idea. To save that time the next time this comes up, I'm writing it down this time around:
-
GC is one of the rare places where speed matters enough to make micro-optimizations of the generated code an important issue. Let's face it, even GCC will be much better at that than SBCL.
-
The Lisp debugger is going to be completely useless at debugging GC problems. That's really something that you want to do with an external debugger, which at the moment means gdb. And while debugging Lisp with gdb is sort of cute the first couple of times, it gets old really fast.
-
Talking about debugging, figuring out GC problems in new ports is already hard enough. It's going to be even harder when there's a very real chance that the GC is getting miscompiled by the freshly ported SBCL. Likewise finding and debugging compiler bugs is going to be much easier when the system has a working GC.
And what do you get for doing the rewrite?
-
The coolness factor.
-
The ability to do some minor GC changes on a running Lisp system instead of waiting for 1.5 minutes while the runtime is recompiled and the GC is sanity-tested by make-target-2.sh compiling PCL.
Even if you don't consider the amount of work required by the GC rewrite, I'm not convinced it would be a good choice for SBCL. Of course some others disagree with this evaluation, which is why the subject keeps coming up :-)
Speaking of the GC, I took another cut at improving the way the GC zeroes memory earlier this month, which gives a pretty big speedup on some systems. This won't be in 0.9.8 (except for the ROOM changes), but maybe in 0.9.9. If somebody wants to test these changes on funny platforms, the patch is available. Meanwhile here's a pretty picture of the results (click on the thumbnail for larger image):
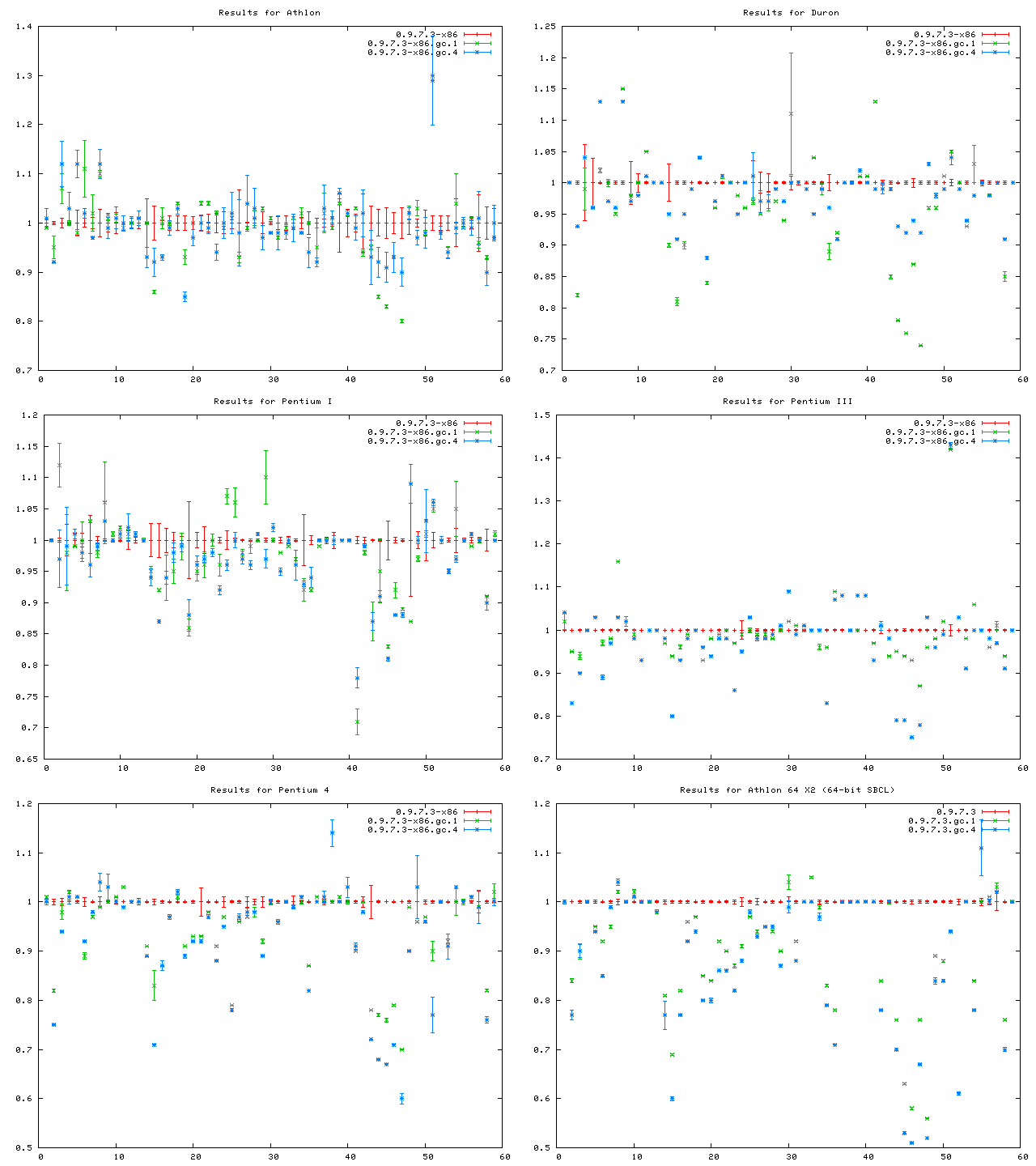
X-axis are benchmarks sorted according to Christophe's benchmark clustering data, y-axis is relative runtime compared to vanilla SBCL. Red dots are vanilla, green dots are with the mmap/munmap-based memory zeroing replaced with memset and the blue dots are using custom assembly versions of bzero instead of memset.