Long time, no blog. I have an excuse though, since I moved to Switzerland for a new job a month ago, and haven't had a lot of time for things like blogging or hacking Lisp (the latter is usually a prerequisite for the former for me).
Anyway, I finally finished and committed the third rewrite of my patch for speeding up the embarrassingly slow hash-tables in SBCL. It turned out to be a really frustrating game of whack-a-mole, with every change uncovering either some new deficiency or another interaction between the GC and the hash-tables that the old implementation had handled by always inhibiting GC during a hash-table operation.
The main user-visible change is that SBCL no longer does its own locking for hash-tables (the fact that it locked the tables was always just an implementation detail, not a part of the public interface). This follows the usual SBCL policy of requiring applications to do take care of locking when sharing data structures between threads.
The exact details are pretty boring, so I won't repeat them here (read the commit message if you really want to know). Instead I'm just going to post a pretty benchmark graph, since it's been way too long since I last did one of these:
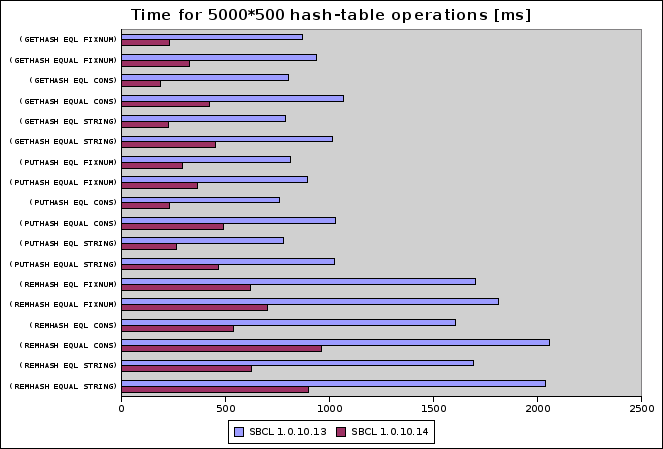
Sadly those improvements don't mean that SBCL now has the fastest hash-tables in the West, it just means they don't completely suck. For some reason the issue of SBCL hash-table speed has come up more often during the last couple of months than during the previous three years combined, so it was probably time to get this sorted out.
Thanks a LOT for your work on this. I have some code that does heavy use of hashtables, and this will really speed up my program! :-)