Last week I needed a timer wheel for a hobby project. That's a data structure that's been reimplemented over and over in the last three decades, but for various reasons I couldn't get excited by any of the freely available ones. Obviously this means that one more implementation was needed, hence Ratas - a hierarchical timer wheel. Unfortunately my vacation ran out before I could get back to the original project, but that's the nature of yak shaving.
In this post I'll first explain briefly what timer wheels are - you might want to read one of the references instead if you've got the time - and then go into more detail on why I wrote a new one.
(Hierarchical) timer wheels
Timer wheels are one way of implementing timer queues, which in turn are used to to schedule events to happen at some future time. If you have tens or hundreds of timers, it doesn't matter much how they're stored. An unsorted list will do just fine. To handle millions of timers you need something a bit more sophisticated.
A timer wheels is effectively a ring buffer of linked lists of events, and a pointer to the ring buffer. Each slot corresponds to a specific timer tick, and contains the head of a linked list. The linked list contains the events that should happen on that tick. So something like this.
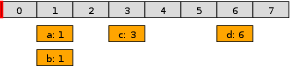
(The pointer is in red, the wheel slots in gray, the events in orange, and the numbers show the time the slot/event is associated with.)
For every tick of time, the pointer moves forward one slot. The slot that was passed will now refer one full rotation to the future. The first slot is no longer tick 0, but tick 8:
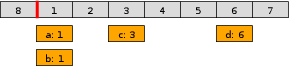
Any events in the slot will get executed as the pointer passes it. So on the next tick events a and b are executed, and removed from the ring.

A timer wheel has O(1) time complexity and cheap constant factors for the important operations of inserting or removing timers. Various kinds of sorted sequences (lists, trees, heaps) will scale worse, and the constant factors tend to be larger. But a basic timer wheel only work for a limited time range. The question is how you extend them to work when the timer range is larger than the size of the ring.
One solution is the hierarchical timer wheel, which layers multiple simple timer wheels running at different resolutions on top of each other. Each field has its own slots and its own pointer.
When an event is scheduled far enough in the future that it does not fit the innermost (core) wheel, it instead gets scheduled on one of the outer wheels. So something like the following, where the timers scheduled for ticks 9 and 13 have been stored in the first slot of the second wheel:
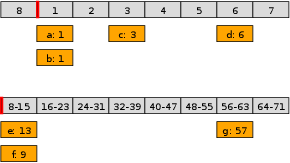
Usually a timer tick will just advance the pointer on the core wheel, working exactly like the simple timer wheel. That's true all the way up to and including tick 7 in this example.

But when the pointer of the core wheel wraps around, the pointer for the second wheel will advance by one slot. The events contained in that slot will either be executed or promoted to the correct slot in the core ring. (As happens here for events e and f).
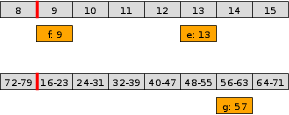
This obviously generalized to more than two layers. A full rotation of any single wheel will advance the pointer by one on the next layer of wheels.
The 1987 paper Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facility by Varghese & Lauck is where the concept of hierarchical timing wheels [0] was introduced. As usual, Adrian Colyer's summary is great if you don't have time to read the full paper.
Single-file implementation, no dependencies
The main reason I couldn't use existing implementations was that the best ones were deeply embedded in larger systems, and would have taken a lot of work to extract into stand-alone libraries. Ratas is a single-file implementation with no external dependencies beyond C++11. So it should be pretty easy to drop into any C++ project.
In a related but equally important point, Ratas doesn't have any internal time source, its notion of time is driven from the outside by the user of the library. This is actually a more important property than might first appear. There are a lot of event loop libraries that have timer queues of some sort, but the event loops by their nature want to be in control of execution. I needed a component to use as part of building a custom event loop instead [1].
Some of the libraries I looked at had interesting implementation strategies. (Wow, DPDK uses skiplists for the timer queue?). It would have been great to run some deterministic benchmarks comparing all these implementations. But in general even a crude hack job to extract the minimum viable free-standing implementation out of them was too much work.
Limiting number of events triggered in a single timestep
One operation that I've wanted in the past is limiting the number of
timers triggered in a single call to the
timer's advance method. If exceeded, the timer
wheel should bail out early, let the application do some work,
and then continue where it left off. This way an unfortunate
clump of timers can't starve the main processing loop for too
long. [2]
Of course the main application loop will need special logic logic, and do more frequent calls to timer processing than normal until the backlog has been dealt with.
This is trivial with a fully ordered event queue. With a timer wheel it means making the timer processing re-entrant as a whole (including the contents of the wheel being modified while it's still in the state between ticks). Luckily there's a way to do this with very little extra wheel-level state and with no changes at all to the event scheduling or canceling logic. So the overhead on the fast path is pretty much immeasurable.
Optimize for high occupancy, not low
One of the perceived problems of timer wheels is that while event insertion and deletion are O(1) operations, finding out the time remaining until the next event triggers is O(m+n) where m is the total number of timer wheel slots and n is the number of events. Specifically, you need to walk through the wheel until you find a slot with some events. Then depending on the resolution of the slot, you might need to walk through the full event chain of that slot. In addition to the algorithmic complexity, both of these operations are effectively pointer chasing, so there will be a lot of cache pollution.
There are various tricks that can be used to make this operation cheaper. For example each wheel could have a bitmap that parallels the array of slots in the wheel. If the bitmap has a 1 in a given position, the slot is non-empty. This allows the implementation to short-circuit the search by skipping the empty slots completely.
I am not convinced this class of optimizations is a good tradeoff. They speed up a couple of operations: looking up time of next event, advancing the time by a lot of ticks in one go, but only if the timer wheel is at a low utilization. In exchange you're paying a small extra cost on every insert and deletion operation. [4]
And here's the thing. If the wheel is at a low utilization, it means that the program as a whole is at low utilization. That's exactly the situation where I don't care about the performance of a component like this. Performance only starts to matter once the system is under load. When the system as a whole is under heavy load, so are the timer wheels. At that point these lookup operations will short-circuit almost immediately, so the optimizations do nothing. On the other hand, that's exactly when the extra overhead added to insertions and deletions will be most significant.
There is however one useful thing we can do on the interface
side to help with the original issue. Every time I've used any
kind of ticks_until_next_event()-like
functionality, it's with a pattern like this:
Tick sleep_usec = std::min(timers.ticks_until_next_event(), 1000);
There's some upper bound on how large a result I'm interested in. Even if there are no timer events to be handled in the next millisecond, there's something non-timer driven that I know will need to happen. So let's just tell the timer wheel what that the upper bound is:
Tick sleep_usec = timers.ticks_until_next_event(1000);
This allows the timer wheel to short circuit the search, and return as soon as it's clear that the wheel contains no events scheduled to happen before that threshold.
Another option for reducing the cost
of ticks_until_next_event is to allow it
to return a lower bound rather than an accurate result.
If the process reaches a slot with more than
one tick of granularity, don't walk through the chain of
events but return the lower bound of that slot's tick
range. I didn't do this since again that feels like
optimizing for the uninteresting case, and since the API would
then need separate accurate and approximate operations.
(Having just the approximate operation available seems wrong).
Range-based scheduling
A lot of timer events get scheduled over and over again, but never executed [3]. Often the exact timing of their execution doesn't matter, but there is a lot of expensive churn as the timer is adjusted by minute amounts. To reduce the churn, Ratas includes a second scheduling interface that takes a range of acceptable times rather than a single exact time. For example:
timers.schedule_in_range(event, 100000, 101000);
It is then up to the implementation to decide on the optimal
scheduling. Right now the implementation
of schedule_in_range decides immediately on a
single tick to schedule the event for. All information on the
range is lost after that, rather than maintained in the long
term. The decision is currently done as follows:
- If the timer is already scheduled in the right interval, just do nothing.
- Prefer scheduling the timer on a exact slot boundary, so that it can be executed in-place rather than promoted to the inner wheel.
- Prefer scheduling the timer as late in the range as possible. This is important to maximize the efficiency of the first point.
Why reify the the timing immediately, and drop the range information? Mostly because it's not clear there's a good time to use that information later on. The main times we're going to look at the event again is when it's up for execution, or when it gets rescheduled. In the first case the range gives us nothing. In the second case we've already gotten a new and improved range.
Using this additional interface didn't make as big a difference as I was hoping for in my benchmark, just about 10%. The reason is that only one of my four timer types was a good match for range-based scheduling. But I don't know that it'd be appropriate for a much higher proportion of real world use cases, so that's fair enough.
Approximate event scheduling is of course not a new concept in any way [5]. And even if approximate scheduling is not supported by the timer library, some parts of it you can emulate on the application level. But even so it seems like something you'd want integrated properly in the library. Native functionality is always more comfortable to use than wrappers.
Finally, there's one more alternate strategy to mitigate the churn of timers creeping later and later. If a timer is already active and is rescheduled further into the future, update its scheduled time but leave the event structure on the ring in exactly the same place. When the event comes up on the wheel, the timer wheel checks the execution time, notices the time is still in the future, and reschedules the event to its proper location instead of executing the callback.
The theory sounds plausible, but in my testing this mostly resulted in small slowdowns. It's of course dependent on the workload, but it's definitely too fragile to use as a default and too obscure to be worth an option. I'd also hate losing the invariant that a slot only contains events with the correct tick.
A benchmark program
I wrote a little benchmark that creates a configurable number of events with a mix of different behaviors:
- Timers with a short duration that get scheduled constantly and are almost always executed.
- Timers with a long duration that are scheduled once, and eventually get executed.
- Timers with a long duration that are constantly rescheduled to happen later, and thus never get executed.
- Timers with a medium duration that get scheduled rarely and get executed once every time they get rescheduled.
- Timers with a medium duration that get scheduled rarely, and are either rescheduled to happen earlier or canceled.
Sets of these timers are grouped into units, with each unit consisting of a total of 10 separate timer events. The work units run at a slightly different cycle lengths to make the access patterns vary a bit over time. There's also a long completely idle period at the end.
The following results were generated by running the benchmark with
various different amounts of 'work units'. Each unit contains a
total of 10 timers (but not all will be active at the same time), and
during the life of a test will schedule about 70k events and end
up executing about 23k of them. The test runtime measured in
virtual timer ticks will always be constant, so increasing the
number of work units will increase the average wheel occupancy
rather than cause more to be done in serial.
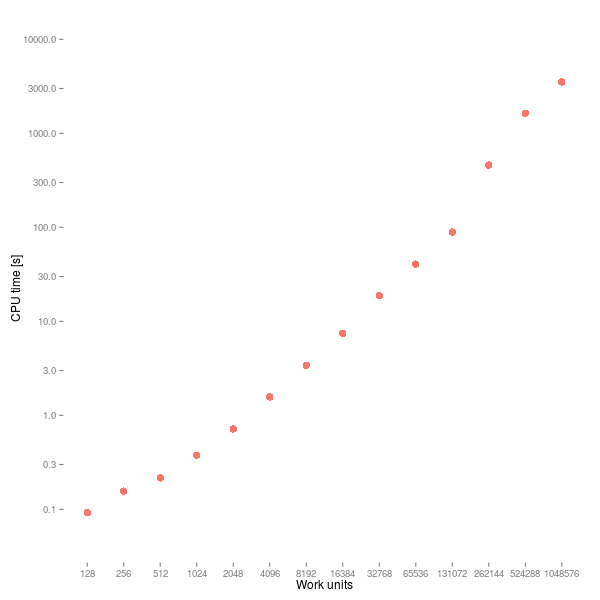
This is a log-log graph, i.e. both the axes are logarithmic. Despite all the important operations being constant time in theory, performance degrades non-linearly and really hits a wall around the 256k work units, where a doubling the workload increases runtime by a factor of 5. It's almost certainly a cache issue. The i7-2640M I ran the tests on has a 4MB cache, so for the 128k work unit case it's already a struggle to keep even the events on the core wheel in L3. So the suboptimal scaling is probably to be expected.
In terms of absolute performance numbers, the 32k work unit workload will do ~120M scheduling operations plus ~40M event executions per second. And on top of that the minor work that the application does in the event handlers. That seems decent for one core of a 5 year old laptop CPU.
No comparative benchmarks, sorry. As I mentioned before, it was hard to find anything to benchmark against. My benchmark program appears to trigger some kind of a performance bug in the only fully featured standalone timer queue I found, which made it perform two orders of magnitude slower than it realistically should have. The primitive operations are much faster than that. I'm sure the problem will get fixed, but right now it doesn't make for a very useful comparison.
Features that didn't make it
There is intentionally no support for repeating timers. I think that kind of thing should be done by the timer explicitly rescheduling itself.
The timer events have a vtable due to the virtual
execute() method. Originally everything was parametrized
at compile time by the callback type, so all events in a single wheel
could use the same execute(). But that really did not
work with the MemberTimerEvent, where the callback is a
combination of a member function specified statically and an object
specified dynamically. I wasn't willing to give up that feature, so
the vtable was a lesser evil.
But it might be neat to allow parametrizing TimerWheel
with a specific TimerEvent. If you need a heterogenous
wheel, instantiate the template with the current
TimerEventInterface. If you can live with a homogenous wheel,
instantiate with some other implementation that has a non-virtual
execute(). I didn't do it since it exceeded my personal
template tolerance, and since homogenous wheels don't feel like a
very compelling use case anyway.
Footnotes
[0] I use the term "timer wheel" instead of the original "timing wheel". The former is what I'd always seen them called until seeing this paper title.
[1] I wrote earlier about why packet processing applications might want a different kind of event loop than typical server applications, and at another time about why determistic control of time is important for testability.
[2] Interestingly this is the opposite of what operating system kernels want to do. They'd prefer to batch as many timers together as possible. The difference here is that I'm thinking of a single-threaded non-locking application, while modern operating systems are all about concurrency.
[3] Think of a timer that deallocates resources after a period of idleness. These might be re-scheduled after every single operation on the resources.
[4] Or maybe not so small a cost; at least I found it tricky to maintain the bitmap without adding an extra back pointer in each event structure or each slot, either of which would be bad news. You could do it without that backpointer by requiring that timers are canceled via the timer wheel, but then you can't have the timers be automatically canceled on destruction. That would be totally unacceptable.
[5] For example Linux already applies a percentage-based timer slack, though for a the purpose of trying to batch as many timer executions together as possible. The LWN article on a proposed replacement to the Linux timer wheel is a good read.
"Performance only starts to matter once the system is under load."
This is not true for soft/hard real time systems, which is where timing wheel variations are often used. Some sort of priority level support would be great.